
中文编码问题是经常遇到的,不复杂但也总是让人头痛的问题,本文阐述QT中遇到的中文编码问题
目录
- 编码流向与乱码的产生
- QT乱码的例子和解析
- 通过设置QTextCodec解决乱码
- QString::fromUtf8不受影响
- codecForName(“System”)
- 禁用QString与char *自动转换
- 源代码编码对程序的影响
- 参考文献
编码流向与乱码的产生
通常读取的流向是下面这样(写入的流向则是反过来):
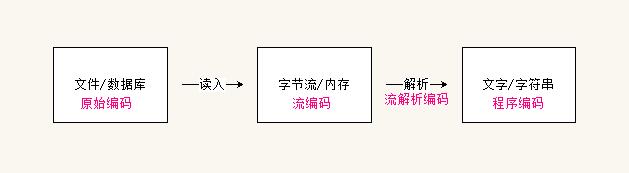
其中:
原始编码: 持久化使用的编码,文本保存的编码,源代码的编码。
字节流编码:文本的字节流,严格来说是没有编码的。但要正确解析字节流,又必须按照其编码,所以其蕴含着一种编码。通常,字节流编码和原始编码一样。
解析编码: 字节流的解析编码。
程序编码: 程序内部字符串的编码。
乱码的产生
上面的流向过程,如果字节流编码和流解析编码不一样,就会出现乱码。这很容易理解。
举例:
原始编码是utf-8,读取时得到utf-8编码的字节流,程序解析时如果使用gb2312编码解析,那么就会出现乱码。当且仅当解析时使用utf-8编码,才能得到正确的字符串。
QT乱码的例子和解析
在开头,贴出VS如何更改源代码的编码(代码页)。文件 - 高级保存选项 - 编码。选择后重新保存当前源文件即可。要检查当前源码的编码,需要使用notepad等可以显示编码的编辑器。
// 源代码编码:gb2312
QApplication app(argc, NULL);
QPushButton btn;
btn.setText("我是中文");
// 或 btn.setText(QString("我是中文"));
// 或 btn.setText(QObject::tr("我是中文"));
btn.show();
return app.exec();
其中:
btn.setText(“”) 等价于 btn.setText(QString(“”)),这是c++特性。
btn.setText(QString(“”)) 等价于 btn.setText(QString::fromAscii(“”)),这是QT内部调用(GB2312使用2个Ascii码编码)。
QObject::tr(“”) 等价于 QString::fromLatin1(sourceText),这是QT内部调用(Latin1是ISO-8859-1的别名)。
之所以出现乱码,是因为我是中文转换为QString过程编码不对应。原始编码是gb2312,解析编码使用的是Latin1。之所以说解析编码使用的是Latin1,这个要看源码了。
QString converts the \c{const char *} data into Unicode using the fromAscii() function. By default, fromAscii() treats character above 128 as Latin-1 characters, but this can be changed by calling QTextCodec::setCodecForCStrings(). QString(““)使用的是fromAscii()函数,默认使用Latin-1,除非设置了CodecForCStrings。
qstring.cpp部分源码
// fromAscii
QString QString::fromAscii(const char *str, int size)
{
return QString(fromAscii_helper(str, size), 0);
}
QString::Data *QString::fromAscii_helper(const char *str, int size)
{
#ifndef QT_NO_TEXTCODEC // 默认没有定义QT_NO_TEXTCODEC
if (codecForCStrings) {
Data *d;
if (!str) {
d = &shared_null;
d->ref.ref();
} else if (size == 0 || (!*str && size < 0)) {
d = &shared_empty;
d->ref.ref();
} else {
if (size < 0)
size = qstrlen(str);
QString s = codecForCStrings->toUnicode(str, size);
d = s.d;
d->ref.ref();
}
return d;
}
#endif
return fromLatin1_helper(str, size);
}
// fromLatin1
QString QString::fromLatin1(const char *str, int size)
{
return QString(fromLatin1_helper(str, size), 0);
}
其中:
codecForCStrings是通过QTextCodec::setCodecForCStrings(QTextCodec::codecForName("GB2312"));设置的,如果没有设置,codecForCStrings为null。
QString::fromAscii等价于QString::fromAscii_helper,如果没有设置codecForCStrings,也等价于QString::fromLatin1和QString::fromLatin1_helper。
也即是说,上面的例子,都等价于使用QString::fromLatin1解析字符串。
那么Latin1到底是什么?是否可以解析GB2312
有些环境下,将ISO-8859-1写作Latin-1。
最早的编码就是ISO-8859-1,属于单字节编码,应用于英文系列。最多能表示的字符范围是0-255(编码范围是0x00-0xFF),其中0x00-0x7F之间完全和ASCII一致(ASCII是7位编码,能个表示128个字符),因此向下兼容ASCII。除ASCII收录的字符外,ISO-8859-1收录的字符还包括西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号。欧元符号等出现的比较晚,没有被收录在ISO 8859-1当中。
很明显,ISO 8859-1编码表示的字符范围很窄,例如无法表示中文字符。但是由于ISO-8859-1编码范围使用了单字节内的所有空间,在支持ISO 8859-1的系统中传输和存储其他任何编码的字节流都不会被抛弃。换言之,把其他任何编码的字节流当作ISO-8859-1编码看待都没有问题。这是个很重要的特性,所以很多情况下(如很多协议传输数据时)都使用ISO 8859-1编码。我们可以这么说,ASCII编码是一个7位的容器,ISO 8859-1编码是一个8位的容器。
比如,虽然“中文”两个字符就不存在ISO 8859-1编码,但可以用iso8859-1编码来“表示”。通过查询下文将要介绍的GB2312编码表,“中文”应该是”d6d0 cec4”两个字符,使用ISO 8859-1编码来“表示”的时候则将它拆开为4个字节来表示,即”d6 d0 ce c4”(事实上,在进行存储的时候,也是以字节为单位处理的)。如果使用Unicode编码,则表示为”4e2d 6587”;使用UTF编码,则是6个字节”e4 b8 ad e6 96 87”。很明显,这种使用ISO 8869-1对汉字进行表示的方法还需要以另一种编码为基础。
上面摘自http://blog.xieyc.com/common-code-standard-unicode-utf-iso-8859-1-etc/,简述就是,ISO-8859-1是单字节编码,相当于字节流,所以当然可以表示其它任意编码,甚至可以表示文件。
QT QString里面默认使用
Latin1,也是因为Latin1可以作为字节流来处理,保证不失真。
可见,上面例子的fromLatin1解析的是ISO-8859-1,而源代码编码是GB2312,编码解析错误,所以QT界面显示乱码。
通过设置QTextCodec解决乱码
从上面的QT源代码(tr是QObject的,没有列出源码)也可以看出,解决乱码的方法,只需要在开头先设置codecForCStrings:
QTextCodec::setCodecForTr(QTextCodec::codecForName("GB2312"));
QTextCodec::setCodecForCStrings(QTextCodec::codecForName("GB2312"));
意思是,QObject::tr("")和QString::fromAscii("")都使用GB2312解析字符串。
这样,源代码编码是GB2312而流解析编码也是GB2312,QString就能得到正确的中文字符串,界面显示就正常。
QString::fromUtf8不受影响
上面设置QTextCodec的编码,对QString::fromUtf8没有影响。看源码。
QString QString::fromUtf8(const char *str, int size)
{
if (!str)
return QString();
if (size < 0)
size = qstrlen(str);
return QUtf8::convertToUnicode(str, size, 0);
}
如上,QString::fromUtf8是直接对字节流进行utf-8解码。
所以,下面的例子里,是否设置QTextCodec都不会有任何影响。
// 源代码编码:utf-8 无Bom(无签名)
QTextCodec::setCodecForCStrings(QTextCodec::codecForName("GB2312"));
QPushButton btn;
btn.setText(QString::fromUtf8("我是中文"));
btn.show();
如上,是否设置QTextCodec和设置为别的编码,对结果都没有任何影响。值得注意的是,QString::fromUtf8只能解析无Bom(无签名)的utf-8编码,而不能解析带Bom(签名)的utf-8编码。无Bom的是Linux等平台下的UTF-8(65001)格式,而带Bom的通常是Window平台下的UTF-8(65001)格式。
codecForName(“System”)
QT内部,使用UTF-16的Unicode编码方式。QTextCodec是用来提供编码的转换器,即QT外部的编码与QT内部的UTF-16之间的相互转换。QT内置了的常见的几种编码转换器,比如ASCII、UTF-8、Latin1。开发者可以实现自己的QTextCodec。
像上面QTextCodec::codecForName("GB2312")这里设置编码是硬编码。而使用QTextCodec::codecForName("System")则会根据环境来选择对应的编码,可以避免源代码编译环境切换导致的编码问题。
下面是QT的文档,摘自https://wiki.qt.io/QtTextCodec
The local 8-bit codec can convert from unicode to the character set specified in the locale and vice versa. This codec is called the “System” codec. This codec can be obtained using QTextCodec::codecForLocale() or QTextCodec::codecForName(“System”).
On Windows, the “System” QTextCodec uses MultiByteToWideChar and WideCharToMultiByte (with CP_ACP - ANSI code page) to convert to and from unicode.
On Unix, coversion is done using iconv. However, Qt can be compiled without iconv support, in which case Qt inspects the LANG, LC_CTYPE, LC_ALL environment variables to determine the codec. The codec detected has to be a part of the Qt built-in codec list (Otherwise, it defaults to latin-1).
意思是:QTextCodec::codecForName("System")等价于QTextCodec::codecForLocale()。在windows平台下,等价于调用本地win32 APIMultiByteToWideChar(CP_ACP)和WideCharToMultiByte(CP_ACP);而在类Unix平台下,等价于使用iconv的QTextCodec转换器。
所以,上面的乱码解决方案,也可以使用下面的方式,而通常也使用下面的方式。因为这种方式没有写死编码。
// 源代码编码:gb2312 或 utf-8带bom
QTextCodec *codec = QTextCodec::codecForLocale(); // 或者 QTextCodec::codecForName("System");
QTextCodec::setCodecForCStrings(codec);
QTextCodec::setCodecForTr(codec);
QTextCodec::setCodecForLocale(codec); // 无需设置,默认就是`System`
QPushButton btn;
btn.setText(QString("我是中文"));
btn.show();
最后的QTextCodec::setCodecForLocale(codec);可以不用设置,因为默认就是System。
使用System后,这里的源代码编码是GB2312、UTF-8带签名(带Bom)或Unicode 1200等等都可以正常显示,而使用UTF-8不带签名(无Bom)则乱码。从源代码(参考下面qtextcodec.cpp中QWindowsLocalCodec::convertToUnicode)可以看到,只是调用了win32 API的MultiByteToWideChar,参数都是CP_ACP(ANSI编码的MultiByte),不知道是MultiByteToWideChar自带的转换效果,还是QT还做了其它处理。总之,测试发现,使用System后,源代码可以为多种编码而界面始终不会乱码,这也是推荐使用System的原因。
上面获取一个Codec的字符串,可以通过下面获取:
QByteArray tmp = QTextCodec::codecForLocale()->name();
QString name = QString(tmp);
QPushButton btn;
btn.setText(name);
btn.show();
QT的各种QTextCodec在Qt\4.7.1\src\plugins\codecs里面。
QT的各种QTextCodec初始化,是在Qt\4.7.1\src\corelib\codecs\qtextcodec.cpp里面的setup()方法。
// textCodecsMutex need to be locked to enter this function
static void setup()
{
if (all)
return;
all = new QList<QTextCodec*>;
// create the cleanup object to cleanup all codecs on exit
(void) createQTextCodecCleanup();
(void)new QTsciiCodec;
for (int i = 0; i < 9; ++i)
(void)new QIsciiCodec(i);
(void)new QFontGb2312Codec; // Gb2312 codec
(void)new QFontGbkCodec; // Gbk codec
(void)new QFontGb18030_0Codec;
(void)new QFontJis0208Codec;
(void)new QFontJis0201Codec;
(void)new QFontKsc5601Codec;
(void)new QFontBig5hkscsCodec;
(void)new QFontBig5Codec;
(void) new QWindowsLocalCodec; // 就是它 Windows下`System`的codec
(void) new QIconvCodec(); // Unix下`System`的codec
if (!localeMapper)
setupLocaleMapper(); // 设置本地lang
}
static void setupLocaleMapper()
{
localeMapper = QTextCodec::codecForName("System");
if (!localeMapper) {
const QByteArray ctype = setlocale(LC_CTYPE, 0); // 具体查看setlocale函数的作用
// environment variables.
QByteArray lang = qgetenv("LC_ALL");
if (lang.isEmpty() || lang == "C") {
lang = qgetenv("LC_CTYPE");
}
if (lang.isEmpty() || lang == "C") {
lang = qgetenv("LANG");
}
}
// If everything failed, we default to 8859-1 // 默认是 `ISO 8859-1`
// We could perhaps default to 8859-15.
if (!localeMapper)
localeMapper = QTextCodec::codecForName("ISO 8859-1");
}
Locale是根据计算机用户所使用的语言,所在国家或者地区,以及当地的文化传统所定义的一个软件运行时的语言环境。也即是说,Locale指示着当前系统的语言和字符集。这个参考http://www.cnblogs.com/xlmeng1988/archive/2013/01/16/locale.html。
禁用QString与char *自动转换
QString string = "我是中文" 或 QString("我是中文")
上面的这种用法,是QT提供的默认转换,将C类型的字符串转换为QString。从上面也可以看到,对于这类字符串,依赖于源文件的编码。
比如,上面的部分例子,如果不注明源代码的编码,那么测试结果很可能为乱码,你需要逐一测试源代码的编码才可能得到正确的显示。
相反,如果使用下面的方式:
QPushButton btn;
btn.setText(QString::fromUtf8("我是中文"));
btn.show();
这种方式,很容易知道,源代码的编码方式必须为UTF-8。
回到正题,禁用QT的C-strings到QString的自动转换,可以通过定义宏QT_NO_CAST_FROM_ASCII来禁用。禁用后,QString(““)会编译失败。
源代码编码对程序的影响
用过MyEclipse写过J2EE的都应该知道,一般需要先将源文件的默认保存编码设为UTF-8,否则总会遇到乱码的问题。
通过上面的例子,也可以看到,源代码的编码对程序的结果产生了影响。
那么这个影响是怎样产生的,可以参照上面的编码流分析,分析程序整个运行过程。
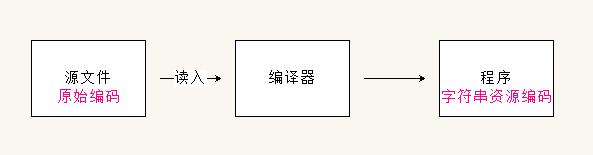
其中,编译过程是影响最大的。
据说,VS编译器在编译的时候,会根据源代码的代码页将其转换为Unicode然后再编译,也即是说,VS编译器能够识别源代码的编码然后正确转换为Unicode。所以,如果按照这种方式,源代码使用gb2312或utf-8对程序都没有影响(说的是思路,至于VS编译器是否这样没有考究)。
而反观QT的代码,源代码的编码对程序产生了影响,所以可以推测,QT的编译器是没有对源代码的编码进行转换的,它将源代码字符串从原始编码转换为Unicode(QT内部字符串也是Unicode)的过程交给了开发者处理。所以,源代码的编码方式对程序的结果产生了影响。
参考文献
qstring.cpp源码,fromAscii、fromLatin1、fromUtf8。qtextcodec.cpp源码,setup、convertToUnicode。- QT wiki https://wiki.qt.io/Strings_and_encodings_in_Qt
- QT wiki https://wiki.qt.io/QString
- QT wiki https://wiki.qt.io/QtTextCodec
- QT wiki https://wiki.qt.io/BasicsOfLocales
- QT wiki https://wiki.qt.io/BasicsOfStringEncoding
- 百度百科,ascii、latin1、gb2312,utf-8。