
构建这个站点所做的一些事情和遇到并解决了的一些问题
目录
Jekyll文章分类问题
如何实现一个类别一个页面
大部分Jekyll站点,文章的类别只是一个页面,并且都是下面这样:
linux
shell简单教程
linux常用命令行
mac
ios开发入门教程
xcode快捷键
windows
windows API入门教程
之所以分类页显示成这样,是因为大部分Jekyll站点都只能这样遍历:
{% for cates in site.categories %}
{{ cates[0] }}
{% for post in cates[1] %}
{{ post.title }}
{% endfor %}
{% endfor %}
-为什么只能这样遍历呢?
-因为你无法预知新文章的分类名叫什么。
曾经见过一个Jekyll站点做成这样,一个类别一个页面
linux.html
shell简单教程
mac.html
ios开发入门教程
它是怎么做到的呢?难道它动态地为每一个分类创建一个页面?
不是的!Jekyll是静态网页系统,页面是在访问前就生成的。
那么,它是访问前就生成了每个分类页?通过遍历生成分类页不是很简单?
不是的!Jekyll目前还没有提供从代码里生成页面的功能,它只是将文本转为页面。仔细查看,不难发现,Jekyll站点能访问到的页面都是事先由博主创建的。比如,首页对应index.html页面,类别页对应category.html页面,文章页对应*.md文件。
好了,回到正题,既然如此如何实现一个类别一个页面展示呢?
思路1
写一个Jekyll模板的插件实现从代码里生成页面的功能,如果这样做,使用github托管时需要将生成的整个站点push上去,因为github pages不能运行第三方插件。
思路2
新类别页自己动手添加,就像添加新文章一样。
如果有一个新类别叫windows,则在Jekyll根目录创建一个windows文件夹,并加入index.html页面,内容为:
当前分类:windows分类
{% for post in site.categories.windows %}
{{ post.title }}
{% endfor %}
这是另一种访问目录文章的方式,不过这种方式目录不能为中文!但是既然整个页面都有了,页面里做什么都可以了,当然也可以写上对应的中文名。
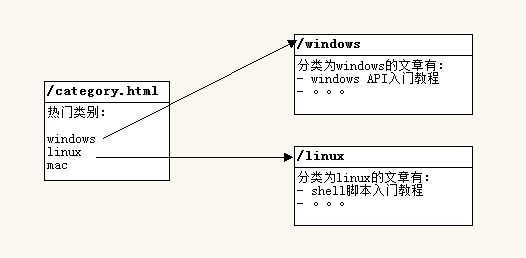
于是,我们可以通过www.xxx.com/windows访问分类为windows的文章列表了。
然后为每个分类生成一个链接,对应的列表为
当前文章分类有:
{% for cate in site.categories %}
<a href="/{{ cate[0] }}">{{ cate[0] }}</a>
{% endfor %}
这样,点击分类名就会跳转到对应的分类页面了。图解:
之前见过的一个分类对应一个页面的实现思路和这里的差不多。因为都是复制粘贴,所以还算能够接受。
思路3
个人比较不喜欢重复做同样的事情,所以就使用另外的方式。
从上面分析可知,要实现一个类别一个页面,仅仅靠静态网页是无法实现的。正如上面所说,你无法预知下一篇文章的类别。所以,我们就只能使用动态页面。
动态页面的生成,可以在前端或后端实现。思路1是后端实现,那么这里就试下从前端实现。
要前端动态生成分类页,很显然我们需要在浏览器中得到文章的列表、类别等信息,这些信息真的能得到吗?
当然,不是一直在遍历站点类别集合、文章集合吗!把它们存储到文件让浏览器访问不就行了。
于是,一个json格式的数据文件postfile就这样诞生了:
{
"posts":
[
{
"title": "一步一步创建Jekyll主题",
"words": "1932",
"author": "jokin",
"date": "2016-09-03 23:47:05",
"url": "/2016/09/03/how-to-create-the-jekyll-theme.html",
"pid": "20160903-154705",
"image": "/w3c/images/jekyll.jpg",
"categories": ["jekyll"],
"excerpt": "讲述当前Jekyll站点的制作过程..."
}
, {... ...}
]
}
Liquid语法是这样:
{
"posts":
[
{% for post in site.posts %}
{
"title": "{{ post.title }}",
"words": "{{ post.content | number_of_words }}",
"author": "{{ site.author }}",
"date": "{{ post.date | date:"%Y-%m-%d %H:%M:%S" }}",
"url": "{{ post.url }}",
"pid": "{{ post.pid }}",
"categories": [
{% for cate in post.categories %}
"{{ cate }}"
{% endfor %}
]
......
}
{% endfor %}
]
}
数据文件有了,剩下的就是在页面访问这些数据组织页面,想做什么都可以了。
注,site.categories 和 post.categories 是不一样的
如何实现文章的子目录作为类别
Jekyll中,文章路径为/windows/api/_posts/2016-9-22-category.md的文章,windows和api会被添加到文章的分类中,即category.md文章的类别为windows和api。
但是这样的分类方式其实很不好,因为文章放得太分散。
为什么不是_posts/windows/api/2016-9-22-category.md这种路径呢?
既然Jekyll不支持这种方式,只好尝试自己实现了。
纵观文章post对象,该对象有一个path字段,表示该文章在Jekyll中的路径。
比如,上面的category.md通过post.path可以得到路径字符串_posts/windows/api/2016-9-22-category.md。有了路径字符串,再使用Liquid语法进行分割,就可以得到子目录windows和api,然后和post.categories里的分类去重合并,就得到了我们想要的将文章子目录作为分类类别的功能。
一旦加了这个功能,在文章中就不能通过post.categories或site.categories访问类别集合了,因为它没有加上子目录。
下面是处理子目录的代码:
站点数据库
正如上面所说,postfile就像站点的数据库。
多说插件
Jekyll没有评论功能,所以需要第三方的评论插件。
用过友言和多说,其实两者都不是太理想。多说提供了开发者的部分API,所以相对来说应该自由很多,所以最后选择了多说。
使用多说插件实现说说功能
在我的博客,我一直希望有这样一个功能,有一个地方展示最近听到的名言,就类似QQ空间的说说。
有一个思路是,利用Jekyll的特性,把文件作为数据库来处理,每次增删改查修改文件即可。
这样虽然能够展示,但是有另一个功能无法实现,那就是别人对说说的评论。
偶然的机会,注意到了多说的评论列表,突然醒悟,这和我想要的效果不是差不多么。
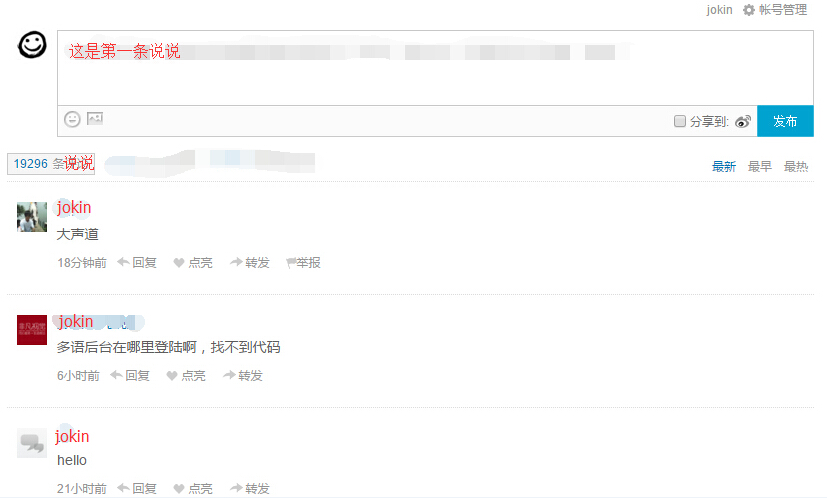
只要:
- 除了自己外,禁止别人对此主题的评论
- 修改文案,使其看起来不像评论
所以,页面展示时,先判断当前用户角色,如果是自己的账号,则展示评论框,自己的评论就会成为一条说说。如果角色不是自己的,则隐藏评论框。
多说原始文案修改
文案的修改思路是,监听多说插件的加载,加载完成的时候,替换成自己的文案。
思路简单,但是多说插件并没有提供加载完成的通知,所以,只好使用轮询来监听,因为页面加载的时间非常短,所以轮询也不会持续太久。
var executeOnLoad = function(selector, loaded_callback) {
var $elements = $(selector);
if($elements.length) {
$elements.each(function(){
loaded_callback.call($(this));
});
} else {
setTimeout(function() { executeOnLoad(selector, loaded_callback); }, 100);
}
}
executeOnLoad(".ds-comments-tab-duoshuo", function(){ this.text("博主的说说"); });
锚点失效
测试过程发现,设置的锚点链接经常不生效,从失效的频率来看,很可能是代码引起的。经过多次对比普通静态页面的锚点与当前页面的锚点,可以猜想原因是这样子:当前页面的锚点的内容是异步加载的,点击锚点链接的时候,页面其实已经跳转到锚点,由于锚点的内容还没加载完成,页面不需要滚动,后来锚点的内容动态加载完成,但页面已经不会再滚动了。反过来,如果锚点的内容及时加载完成,锚点就能正常跳转。这就是锚点总是失效的原因。
要解决这个问题,必须保证锚点操作前,锚点节点已经加载完成;或者锚点节点加载完成的时候,再执行一次锚点跳转。
锚点链接是浏览器的行为,所以这里只能在节点加载完成的时候,再次执行锚点跳转。
由于锚点节点就是多说插件,所以无法知道它什么时候加载完成,也只好同样使用了上面的轮询方式。如果有Dom节点监听事件,应该会比轮询要好。
// if found .ds-comments-info then consider comments has loaded
executeOnLoad(".ds-comments-info", function(){
if ( $(window.location.hash).length > 0 ) {
$(window).scrollTop( $(window.location.hash).offset().top );
}
// hash就是锚点
});
TOC目录
为什么要说TOC目录呢,因为在这里学到了一点有用的东西 ![]()
说起markdown的TOC目录自动生成,只是看到网上各种教程说那样使用,其实并没有说明具体的语法。
因为markdown解析器是kramdown,所以我尝试在kramdown的官方文档、Github仓库里查找,结果并没有发现TOC目录的任何语法说明。
后来看到kramdown的简介: kramdown (sic, not Kramdown or KramDown, just kramdown) …这段挺风趣… various extensions that have been made popular by the PHP Markdown Extra package and Maruku.
于是猜想,TOC不会是继承于PHP Markdown 或 Maruku吧。
结果,在Maruku的文档里,惊喜的发现了少量不太详尽,但至少说明了TOC目录语法的文档。
SEO
某日走在路上,突然想起网站SEO,SEO是什么缩写呢?脑袋里竟然一字一句的推敲出了Search Engine Optimization,因为曾经听说,SEO并不是一开始就有的,是有了搜索引擎后针对搜索引擎的搜索规则才衍生出的词,所以轻易就推导出Search Engine,后面的Optimization是因为VC总是有个O选项表示优化。
搜索引擎优化,说白了就是迎合搜索引擎的搜索规则而进行的优化。所以真正要优化,需要了解具体的某个搜索引擎的规则。
当前站点只是做了普通的SEO。