
写完上一篇短文的时候,想到了第一个点,那就是URL的中文问题
目录
- URL格式
- URL能直接使用中文吗
- 站长工具得到的UTF8编码为什么和URL里的UTF8编码的不一致
- 浏览器的地址栏为什么能够显示为中文?
- 实例:本站点URL地址中的中文处理
- encodeURI与encodeURIComponent区别
URL格式
协议://IP域名[:port]/[path][?param1=value1¶m2=value2][#fragment]
http://www.jokinkuang.info:80/article.html?category=frontend#comment
协议常见的有 http 、 https 、 ftp://固定尾随在协议后面,解释了为什么URL是这样的形式: http:// 、 https:// 、 ftp://IP域名可以是IP,也可以是域名。比如:127.0.0.1或localhost:port默认端口是80。比如指定端口4000:localhost:4000path?param=value参数与值#fragment锚点,也叫hash,英文搜索时使用hash会更准确
[ ]表示可选
把上面的所有可选都去掉,最简的URL就是 协议://IP/,也即是 http://www.jokinkuang.info这样
URL能直接使用中文吗
URL是RFCXXX(比如RFC 1738)规定的,目前只有字母数字和它指定的部分符号才能使用。既然是个标准,说不定以后会变。目前的标准是,中文不能直接使用。
计算机世界是,不能用不代表就没有办法。现在通常的做法是,将中文转换为字符编码最后转化为URL编码,字符编码几乎都是数字,所以可以安全地转换为URL编码。
支持中文的字符编码有很多种,其中常见的有:utf-8(unicode),gbk,gb2312。
utf-8是Unicode的一种实现方式,Unicode只是一种使用4个字节表达字符的一种编码。
所以中文转换为字符编码的过程就有很多选择,这意味着,选择不同,最终的URL编码也会不同。
一般,通常情况下,浏览器会使用utf-8编码:
以我字为例,它的utf-8编码是E6 88 91,再转换为URL编码是%E6%88%91
但不能排除有的浏览器会使用gbk编码:
我字的gbk编码是CE D2,再转换为URL编码是%CE%D2
所以,具体问题具体分析,如果中文转换为字符编码的过程是你自己控制的,那么解码时你指定对应的编码即可,如果这个过程不是你控制的(比如是浏览器控制的),那么你需要分析这个过程使用的编码,这样你才能从URL中得到正确的中文。
站长工具得到的UTF8编码为什么和URL里的UTF8编码的不一致
为了验证UTF8编码到URL编码的转换过程,我特地在站长工具里将我中文转换为UTF8编码,但结果并不是期待中的E6 88 91,而是我,这是怎么回事?

首先,我把我字存储为utf-8格式的文本,使用16进制查看器,结果是E6 88 91,这和预期的一样。

站长工具里得到的编码是什么呢?为什么会不一致?
经过一番搜索,最后在http://www.fileformat.info/这个网站得到了答案
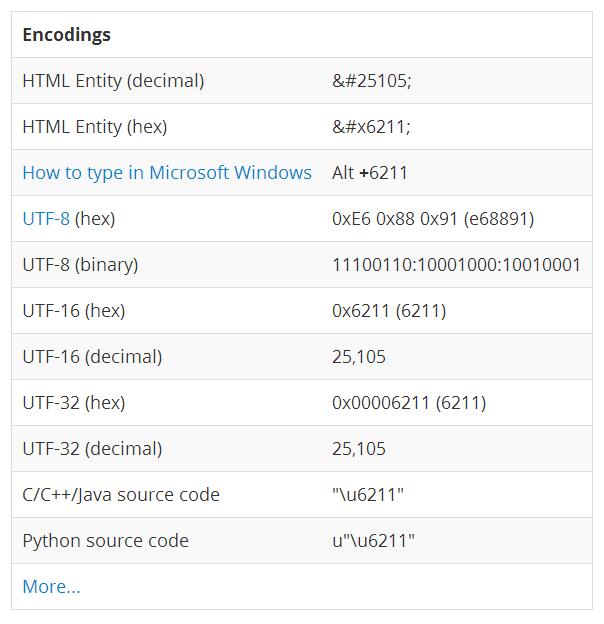
原来站长工具的utf-8编码并不是真正意义的utf-8编码,只是html语法中使用16进制输出一个utf-8格式的字符的语法。
我
我
把上面的文字保存为test.html,用浏览器打开就能看到两个我字,但这并不是真正意义上的我字的utf-8编码。
浏览器的地址栏为什么能够显示为中文?
既然URL不支持中文,为什么浏览器能够显示网址路径为中文呢?

不知道什么时候开始的,浏览器认为网址里一大串奇妙的数字,不直观,于是,将地址栏里的这串奇怪的数字转码并显示为中文,方便阅读。注意,浏览器并不是修改了原来的网址,它只是用另一种方式显示,内里还是原来的URL地址。
复制上图里面的中文网址,粘贴到文本,就能得到原始的URL地址:
http://www.jokinkuang.info/article?category=%E5%89%8D%E7%AB%AF
实例:本站点URL地址中的中文处理
这个站点的URL包含分类信息,分类可能为中文,所以需要处理中文编码的问题,将中文目录转换为URL编码,然后再通过URL获取其中包含的中文分类。
中文目录转换为URL编码:

这里,没有自己转换中文,而是交由浏览器自动处理含有中文的网址。这里埋下了一个缺陷。
- 浏览器如何处理中文是不可确定的。
它可能有以下的可能:
- 丢弃非标准URL的字符,也即是忽略中文
- 使用gbk编码中文
- 使用utf-8编码中文
- 你所想象不到的处理方式
所以,此站点的做法是不完善的。假想浏览器会使用网页的charset meta进行中文URL编码,本站点的charset是utf-8,所以脚本会使用utf-8进行URL解码(注:未作深入考究,也可能,现在的浏览器都使用UTF-8编码,即使如此,下面的代码仍旧生效,因为本页面的charset是utf-8,脚本会始终使用utf-8解码。
// get URL parameters
function getUrlParam(name) {
var re = /<meta.*charset=([^"]+).*?>/i;
var charset = document.documentElement.innerHTML.match(re)[1];
var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)");
var r = window.location.search.substr(1).match(reg);
// window.location.search 是指 "path?param=value" 中问号后面的字符串 "?param=value"
// substr(1) 是指 "param=value"
// match 是查找得到包含 "value" 的数组
if (r != null) {
if (charset == "utf-8") {
// alert("document charset utf-8");
return decodeURIComponent(r[2]); // encode/decodeURIComponent 使用 UTF-8 编解码
}
else {
// alert("document charset gbk");
return unescape(r[2]); // ECMAScript v3 已从标准中删除了 unescape() 函数,并反对使用它
}
}
return null;
}
注释:ECMAScript v3 已从标准中删除了 unescape() 函数,并反对使用它,因此应该用 decodeURI() 和 decodeURIComponent() 取而代之。
如何修复上面的问题?
不要直接使用含中文的URL,不要让浏览器转码,而是自己转码,使用URL编码后的地址/article?category=%E5%89%8D%E7%AB%AF作为链接,这样自己的脚本里就知道该URL地址的编码方式,也就可以安全的转码。
encodeURI与encodeURIComponent区别
上面出现了encodeURI和encodeURIComponent,所以一般情况下,都会看看这两者有什么区别。
相同:两者都是对一个URI进行编码,并且都不会对ASCII字母和数字进行编码,也不会对这些ASCII标点符号进行编码:- _ . ! ~ * ' ( )
区别:前者会保留URI组成符号,后者连URI组成符号也进行编码
测试:对http://www.jokinkuang.info/article?category=前端分别执行
<script type="text/javascript">
document.write(encodeURI("http://www.jokinkuang.info/article?category=前端"))
document.write("<br />")
document.write(encodeURIComponent("http://www.jokinkuang.info/article?category=前端"))
document.write("<br />")
document.write(encodeURIComponent("http://www.jokinkuang.info/article?category=前端 ,category/"))
document.write("<br />")
</script>
输出结果分别是:
http://www.jokinkuang.info/article?category=%E5%89%8D%E7%AB%AF
http%3A%2F%2Fwww.jokinkuang.info%2Farticle%3Fcategory%3D%E5%89%8D%E7%AB%AF
http%3A%2F%2Fwww.jokinkuang.info%2Farticle%3Fcategory%3D%E5%89%8D%E7%AB%AF%20%20%20%20%2Ccategory%2F
总结:
encodeURI只会对空格、中文、特殊字符等进行编码,不会对URI的组成符号;/?:@&=+$,#进行编码。
encodeURIComponent不仅会对空格、中文、特殊字符等进行编码,还会对URI的组成符号;/?:@&=+$,#进行编码。
如果是URI的一部分,比如参数是协议、主机名、URL路径、查询字符串等,则需要先对参数值执行encodeURIComponent才加到URI参数里。
如果是直接可访问的URI,则直接执行encodeURI。
实例:
把http://www.jokinkuang.info/article?category=前端作为URI参数传递
<script type="text/javascript">
// 1. encodeURIComponent
document.write(encodeURIComponent("http://www.jokinkuang.info/article?category=前端")); document.write("<br />");
// 2. encodeURI
var uri = encodeURI("http://www.baidu.com?url="+encodeURIComponent("http://www.jokinkuang.info/article?category=前端"));
document.write(uri); document.write("<br />"); document.write("解码<br />");
// 3. decodeURI
document.write(decodeURI(uri)); document.write("<br />")
// 4. decodeURIComponent
document.write(decodeURIComponent(decodeURI(uri))); document.write("<br />")
</script>
输出
http%3A%2F%2Fwww.jokinkuang.info%2Farticle%3Fcategory%3D%E5%89%8D%E7%AB%AF
http://www.baidu.com?url=http%253A%252F%252Fwww.jokinkuang.info%252Farticle%253Fcategory%253D%25E5%2589%258D%25E7%25AB%25AF
解码
http://www.baidu.com?url=http%3A%2F%2Fwww.jokinkuang.info%2Farticle%3Fcategory%3D%E5%89%8D%E7%AB%AF
http://www.baidu.com?url=http://www.jokinkuang.info/article?category=前端
从结果来看,
encodeURIComponent的结果再执行encodeURI,还是会再进行编码,比如%会被再次编码为%25。
decodeURIComponent可以将整个URI作为参数解码。